How does Alkira ensure high availability and resiliency for cloud networks?
Alkira's Network Infrastructure-as-a-Service platform is architected for high availability and resiliency. It uses globally distributed Alkira Cloud Exchange Points (CXPs) deployed across multiple availability zones and regions, eliminating single points of failure. All connections are multihomed by default, and the platform supports cross-region and inter-cloud failover, allowing traffic to reroute automatically in the event of regional or provider outages. Proactive monitoring, clustering, load balancing, and annual disaster recovery testing further enhance resiliency. Learn more.
What happens to customer traffic if the Alkira portal (control/management plane) experiences an outage?
The Alkira architecture decouples the control/management plane from the data plane. If the portal becomes unavailable, customer traffic continues to flow uninterrupted. Only the ability to make changes or updates to the network is temporarily affected. Source.
What are Alkira’s SLAs for uptime and recovery?
Alkira provides documented enterprise-grade uptime SLAs, Recovery Time Objectives (RTO), and Recovery Point Objectives (RPO). Daily backups and annual disaster recovery testing ensure compliance with these commitments. Source.
How does Alkira handle cloud region or provider outages?
Alkira supports cross-region and inter-cloud failover. Customers can configure backup connections to CXPs in other regions or even other cloud providers. In the event of a regional or provider outage, traffic is automatically rerouted to these backup CXPs, ensuring business continuity. Source.
How does Alkira simplify the configuration of high availability for non-experts?
Alkira offers a drag-and-drop interface and default redundancy options, making resilient network design accessible even to non-technical users. Automated redundancy and intuitive controls reduce the complexity typically associated with high availability configurations. Source.
Features & Capabilities
What are the key features and benefits of Alkira’s platform?
Alkira provides Network Infrastructure-as-a-Service (NIaaS), global backbone-as-a-service, integrated security (including Zero Trust Network Access and next-generation firewalls), a drag-and-drop interface, comprehensive single-pane-of-glass visibility, and flexible pricing models. Key benefits include up to 96% reduction in cloud setup time, 47% reduction in network management time, 70% faster mean-time-to-resolution, and up to 40% lower total cost of ownership compared to traditional solutions. Learn more.
What integrations does Alkira support?
Alkira integrates with leading technology providers and platforms, including Cisco SD-WAN, Palo Alto Networks, Fortinet NGFW, F5, Splunk, ServiceNow, Infoblox, Aruba SD-WAN, Terraform, and Itential Automation Platform. These integrations enable secure, scalable, and automated cloud networking. See all partners.
Does Alkira offer APIs for integration and automation?
Yes, Alkira provides APIs, including billing APIs that deliver real-time cloud network cost data. These APIs can be integrated with other cost management tools and dashboards, supporting automated monitoring and optimization of cloud costs. Learn more.
What security and compliance certifications does Alkira have?
Alkira is SOC 2 and PCI-DSS compliant, demonstrating a commitment to securing customer data and maintaining robust operational controls. The platform also integrates advanced security features such as Zero Trust Network Access (ZTNA) and next-generation firewalls. See compliance details.
Where can I find technical documentation for Alkira’s solutions?
What is Alkira’s pricing model and how is it determined?
Alkira offers flexible pricing models, including consumption-based (pay-as-you-go) and commitment-based options. Pricing is determined by the quantity and size of network elements (such as Alkira Cloud Exchange Points), connectors, next-generation firewalls, and data egress. Fixed hourly rates are available for specific connector types and bandwidth. Customers can view live pricing details from the portal or via APIs. See pricing.
How does Alkira demonstrate value and ROI?
Alkira delivers measurable ROI, including up to 96% reduction in cloud setup time, 47% reduction in network management time, and up to 40% lower total cost of ownership compared to traditional solutions. These efficiencies translate into significant operational and cost savings. Learn more.
Customer Pain Points & Solutions
What common pain points does Alkira address for enterprises?
Alkira addresses several key pain points:
Eliminating single points of failure in cloud networking through multi-zone and multi-region redundancy.
Mitigating the impact of cloud region or provider outages with cross-region and inter-cloud failover.
Reducing slow recovery and data loss during outages via daily backups and tested disaster recovery plans.
Simplifying the complexity of configuring high availability with a drag-and-drop interface and automated redundancy.
These solutions are designed to ensure business continuity and operational efficiency. Source.
How does Alkira solve the problem of securing distributed workforces and applications?
Alkira integrates advanced security features such as Zero Trust Network Access (ZTNA) and next-generation firewalls directly into its platform. This approach eliminates vulnerabilities found in traditional VPNs and perimeter-based security models, ensuring secure connectivity for distributed teams and applications. Learn more.
How does Alkira address complexity in multicloud and hybrid cloud networking?
Alkira simplifies networking across single, multicloud, and hybrid environments through its global backbone-as-a-service and true abstraction layer. This eliminates intricate configurations and manual setups, reducing deployment times from months to minutes. Learn more.
How does Alkira provide comprehensive visibility and governance?
Alkira offers single-pane-of-glass tools for monitoring, managing, and optimizing cloud networks. This unified approach ensures businesses maintain control and transparency, addressing challenges related to fragmented tools and inefficiencies. Learn more.
How does Alkira ensure high-performance networking?
Alkira leverages its global backbone-as-a-service to deliver scalable, reliable, and low-latency connectivity. The platform automatically adjusts network infrastructure to match bandwidth demand, supporting rapid scalability and high-performance networking. Learn more.
Use Cases & Customer Success
Who can benefit from Alkira’s solutions?
Alkira is designed for mid-to-large enterprises across industries such as manufacturing, healthcare, telecommunications, financial services, biotechnology, software technology, retail, media & entertainment, and aviation. Target roles include Network, Cloud, and Security Architects, IT Managers, CloudOps, CTOs, CIOs, and CISOs. See customer stories.
Can you share specific case studies or customer success stories?
Yes. Notable examples include:
Michaels: Transformed its network across 1,400 stores in record time, ensuring secure and seamless connectivity during peak season. Read the case study.
Koch Industries: Simplified multicloud networking and improved agility. Watch the video.
Warner Hotels: Enhanced networking efficiency, control, and visibility. Watch the video.
Chart Industries: Improved agility, saved costs, and expanded globally. Watch the video.
SITA: Integrated on-premises and cloud environments for the aviation industry. Watch the video.
What feedback have customers given about Alkira’s ease of use?
Customers consistently praise Alkira for its intuitive drag-and-drop interface and rapid deployment. For example, a Network Architect at a large manufacturer reported, "The IT DIY approach was going to take 6 months to be secure and redundant and all. Alkira did it for us in 3 days, and at very low cost." Matt Hoag, CTO at Koch Industries, said, "We had gone from a mass of complexity and months of work to a dashboard that allowed us simply to draw our network and deploy it in a few hours." See more testimonials.
How quickly can Alkira be implemented?
Customers can implement a proof of concept in as little as 4 hours, with full production deployment typically taking around 8 weeks. The platform’s ease of use and dedicated training resources accelerate adoption. Alkira Training Platform.
Competition & Comparison
How does Alkira compare to traditional cloud networking solutions?
Alkira eliminates manual configuration, offers integrated security, and provides automated redundancy across zones, regions, and clouds—features that are often missing or complex in traditional solutions. The platform also delivers measurable operational efficiencies and cost savings. Learn more.
How does Alkira differ from competitors like Aviatrix, Prosimo, Nefeli, and Cato?
Alkira offers a true abstraction layer leveraging cloud providers' infrastructure, single-click provisioning, and end-to-end solutions for both cloud and traditional network use cases. Unlike Aviatrix (which focuses on orchestration overlays), Prosimo (application-centric networking), Nefeli (agent-based solutions), and Cato (SD-WAN focus), Alkira provides full-stack networking, integrated security, and global backbone-as-a-service for multi-cloud and hybrid environments. See detailed comparison.
Why should a customer choose Alkira over alternatives?
Alkira stands out with its true abstraction layer, integrated security, ease of use, global backbone-as-a-service, measurable ROI, vendor-agnostic approach, and comprehensive visibility. These features enable rapid deployment, secure connectivity, and operational efficiency without vendor lock-in. Learn more.
Support, Implementation & Training
What support and training does Alkira provide to customers?
Alkira offers a dedicated training platform with detailed guidance, demos, and resources. Customers benefit from 24×7 monitoring, proactive notifications, a diagnostics dashboard for troubleshooting, and dedicated support via email or support tickets. These resources ensure smooth onboarding and ongoing operations. Alkira Training Platform.
How does Alkira handle maintenance, upgrades, and troubleshooting?
Alkira provides proactive notifications for planned or emergency maintenance, a live diagnostics dashboard for troubleshooting, 24×7 monitoring to meet SLA commitments, and dedicated support for issue resolution. This comprehensive approach minimizes downtime and operational disruptions. Contact support.
Company Information & Vision
What is Alkira’s vision and mission?
Alkira's vision is to transform enterprise connectivity by simplifying cloud networking for the AI era. Its mission is to eliminate the complexity of traditional hardware-dependent networking by providing a cloud-native solution that seamlessly connects hybrid and multi-cloud environments through a unified control plane. Learn more.
What is Alkira’s company background and industry recognition?
Alkira was founded by the creators of Viptela (acquired by Cisco in 2017) and has been recognized as a Gartner Cool Vendor, a Forbes Best Startup Employer, and a recipient of the 2024 Excellence Award from Cloud Computing Magazine. Alkira is also listed on CRN’s 2023 Stellar Startups List. Learn more.
The Alkira Network Infrastructure-as-a-Service platform is built in the cloud and for the cloud. It offers enterprises a platform which allows them to onboard workloads hosted with public cloud providers and connect them with other cloud workloads, on-prem branches, data centers, and globally-distributed users. So, any enterprise leveraging Alkira will have most of their critical traffic traversing through our infrastructure, and as a result the team here at Alkira takes extraordinary strides to make sure that it is fully secure, highly available and built to recover itself in different failure scenarios.
The Alkira Network Infrastructure-as-a-Service is based on a network of globally distributed Alkira Cloud Exchange Points (CXPs), deployed inside hyper-scale public cloud infrastructure. Alkira CXPs are interconnected over high bandwidth, low latency infrastructure. Customers can connect users, branch locations and cloud workloads to the geographically closest Alkira CXP, improving overall application performance by shortcutting the last-mile access over less efficient and less predictable Internet transport.
In terms of availability of the infrastructure, Alkira commits uptime SLA (Service Level Agreement), RTO (Recovery Time Objective) and RPOs (Recovery Point Objective) to its customers. Additionally, Alkira services also offer features to enhance network availability beyond the committed SLAs. In this blog we are going to cover both aspects of the solution and how customers can leverage them.
Availability of the Portal (Control and Management Plane)
There are three elements which makes an infrastructure highly available, first is to have enough redundancy built into the architecture so that there is not a single point of failure, secondly there needs to be proactive monitoring of the application so that you can be notified of the problem ahead of time, and lastly a failover mechanism to switch traffic to backup paths in case of a failure scenario.
The Alkira portal is hosted inside public cloud infrastructure, where there are multiple levels of resiliency and redundancy built-in at different layers of the system. Clustering and load balancers are implemented to have multiple nodes for any given function so that there is not a single point of failure. Nodes required to run applications span across different availability zones and regions to withstand datacenter or a complete regional failure inside the cloud service provider.
In addition to this high level of redundancy, the infrastructure is designed for resilience. Additionally, contingency plans are in place and tested on a regular basis to ensure minimal service impact to our customers in case of an outage within the cloud service provider network.
Data backup is performed for all the nodes on a daily basis so that in case of a failure they can be easily restored within the committed Recovery Time Objective (RTO) and Recovery Point Objective (RPO). There is a Business Continuity Plan and a Disaster Recovery Plan defined which is reviewed and tested annually. Testing is to help ensure that documented plans and procedures are functioning as designed and they get updated immediately in case there are any issues identified during testing. The Business Continuity Plan and Disaster Recovery Plan cover:
Business impact and criticality analysis
Procedures for responding to emergencies related to the production environment
Restoration of lost data
Continuing security during emergencies; and
Emergency access procedures
From an architecture perspective, the system is designed in such a way that the access to the application is completely decoupled from the data plane. In case of a problem with the portal, there will not be any impact to customer traffic and their network; the only thing which will be affected is the ability to do any changes or updates to the current network.
Availability of Alkira CXPs (Data Plane)
Alkira Cloud Exchange Points (CXPs) are deployed in different availability zones for redundancy. All the connections from users, branches and workloads will be multihomed to CXP in each availability zone. This way there will not be a single point of failure and even if there is an outage to an availability zone, there will be no impact to the customer’s network as the traffic can continue to flow through the redundant connection to other availability zone seamlessly.
Figure: Cloud Availability Zone Redundancy
This takes care of an availability zone failure inside the cloud service provider and it is a default option for configuring any connector. But this only works when there is an availability zone failure. In case if there is an outage which affects the cloud service provider region, the customer’s network will still be impacted even if you have connections with multiple availability zones.
Region failure is rare but it does happen and can impact the availability of applications and connectivity of users. With Alkira, you can also design your network to withstand cloud region failure as well. Alkira offers a feature to set up CXP failover for cross-region redundancy. In this case, a CXP failover option can be enabled for a connector while configuring it. Once configured, a backup connection is created with a CXP in another region. By default, the backup connections will be disabled and will be enabled when CXP failover is triggered.
Figure: Cloud Region Redundancy
Lastly, since the CXPs can be deployed in any hyperscale cloud service provider, Alkira can offer inter-cloud redundancy with inter-cloud failover to its customers. Enterprises can design their network to host CXPs in different cloud service providers so that in case there is an outage in one of the cloud providers, the user and application traffic can still route through the other provider.
Conclusion
In this blog I have discussed options which an enterprise can leverage out of box to provide protection against different types of failure scenarios. In addition, there are features which can be configured on top of the default options to even enhance and improve the availability of the network even further. However, it depends on the customer’s business requirement on to what extent they would like to leverage these features as there is cost related to these options. For instance, in order to achieve inter-region failover you will need to run two parallel infrastructures, one for each region at all times.
So in conclusion, the good news is that Alkira allows you to design your network with maximum redundancy to withstand all different kinds of failure but you should evaluate them closely against your business requirements.
Misbah Rehman is VP of Product Management and Compliance at Alkira Inc. He has more than 17 years of experience in networking with a passion in building and managing service provider scale networks and solutions. During his career, he has worked in different technical roles across engineering, sales, technical marketing and product management. Prior to joining Alkira, he was a Sr. Manager for Technical Marketing in the Enterprise Business unit at Cisco where he provided technical leadership to Tier I service providers and helped them create managed service using Viptela SDWAN solution. Misbah holds a Masters degree in Telecommunications from University of Colorado at Boulder.
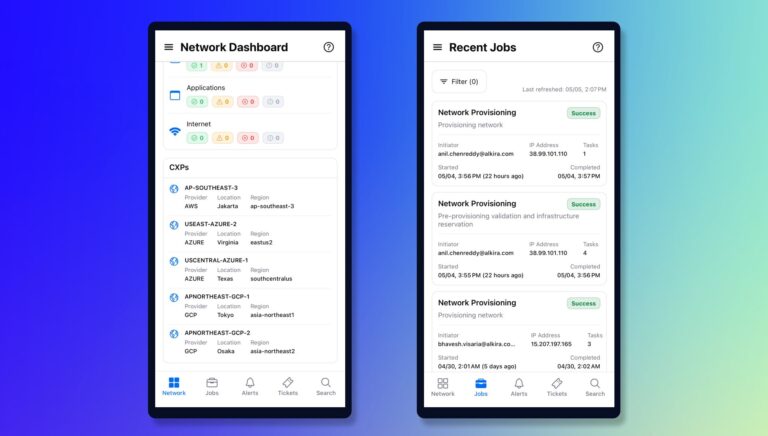
Enterprise networks are expected to run 24/7, and the teams responsible for them need visibility wherever work happens. Cloud environments, partner connections, security services, and provisioning workflows are constantly changing. When something needs attention, network and operations teams need a fast way to understand what happened, assess impact, and take the right next step. That...
Enterprises are moving quickly on AI, but many are still running networking models designed for a slower, more centralized and static era. Today’s network has to connect clouds, data centers, campuses, branches, partner environments, and increasingly private AI infrastructure while enforcing consistent policy across all of it. That creates a new operational reality: every new...
The Digital Operational Resilience Act (DORA) is reshaping how financial institutions in the European Union manage operational risk related to information and communication technology (ICT). As the regulation takes effect, organizations must ensure that their critical ICT service providers support strong operational resilience, risk management, and oversight capabilities. For technology providers supporting financial institutions, this...




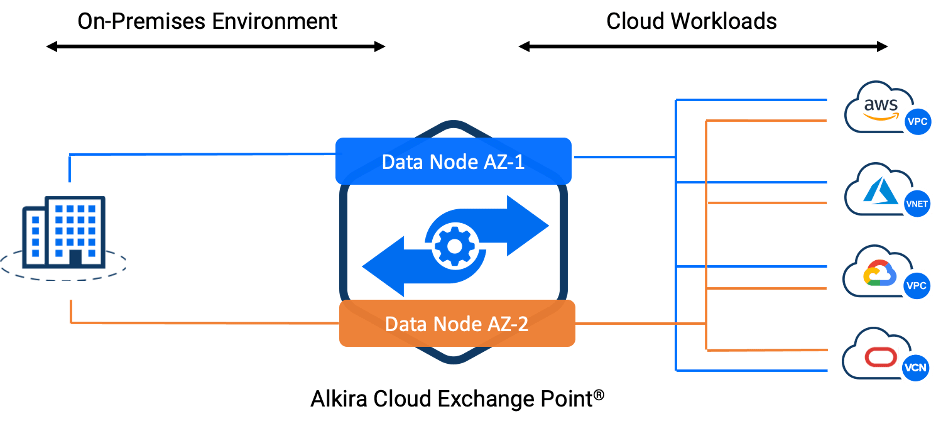 Figure: Cloud Availability Zone Redundancy
Figure: Cloud Availability Zone Redundancy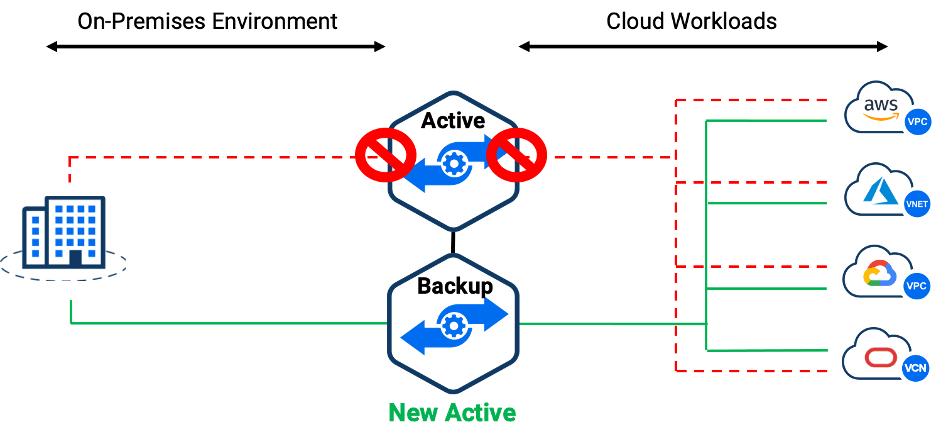 Figure: Cloud Region Redundancy
Figure: Cloud Region Redundancy